Trunking Recorder Call Transcribe
Call Transcribe enables selected recorded calls to be transcribed using the OpenAI Whisper Speech-to-text services. Calls that trigger a Call notification email will also automatically be transcribed.
Trunking Recorder supports using "Speaches" which is an OpenAI API-compatible server powered by faster-whisper speaches GitHub
"Speaches" can be locally hosted and has GPU and CPU support
It can be deployed via Docker Compose / Docker.
Note: Trunking Recorder should work with any OpenAI API-compatible transcription server/service, but has not been tested with any at this time.
To enable OpenAI Whisper "Speaches" Call Transcribe:
- Install and configure "Speaches" (Recommended to install it on a machine other than the Trunking Recorder server) "Speaches" Installation
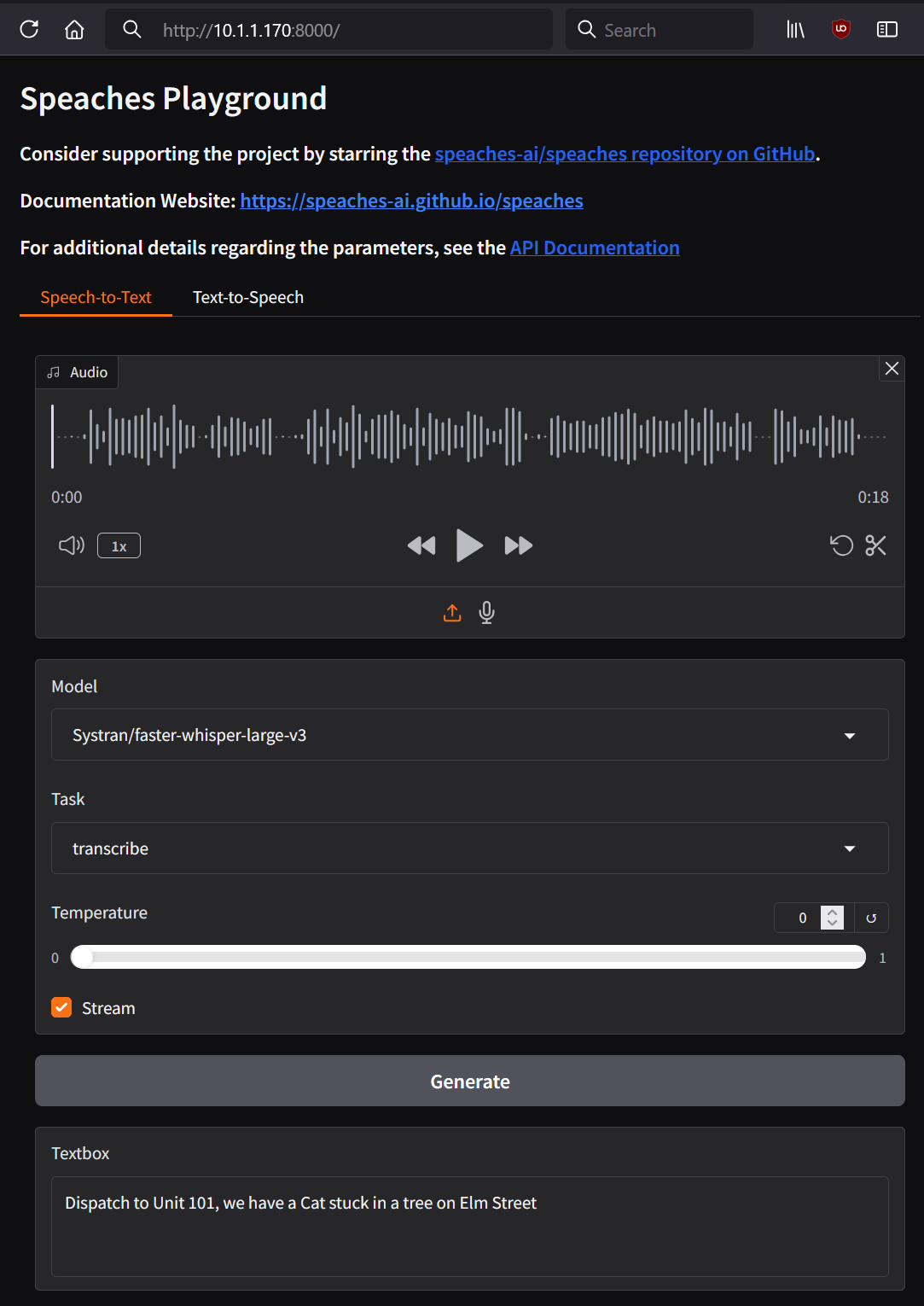
- Access the "Speaches" Playground web interface (Default port is 8000).
- Upload a call MP3 or WAV file from Trunking Recorder and verify that "Speaches" is able to generate a transcription of the audio. You can test various models to see which one works the best for your setup (accuracy, performance, hardware resources, storage, audio environment).
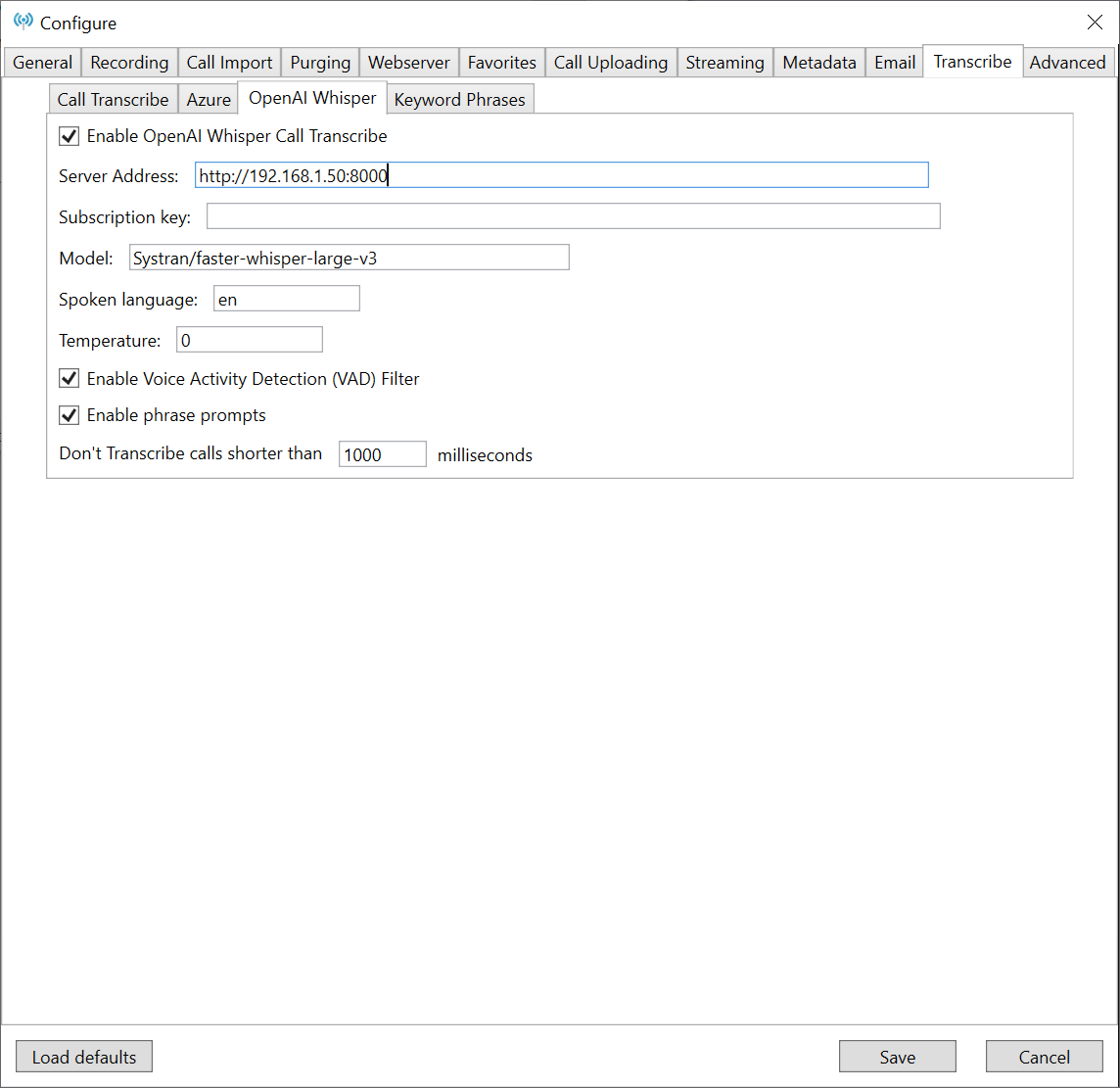
- In Trunking Recorder click the "File" menu item at the top and then select the "Configure" option.
- From the Configure menu select the "Transcribe" tab.
- Click the "OpenAI Whisper" tab.
- Check the "Enable OpenAI Whisper Call Transcribe" checkbox.
- Enter your "Speaches" server URL. (Example: "http://192.168.1.50:8000")
- By default, "Speaches" does not require a subscription key so you should be able to leave this blank.
- Enter the model "Speaches" will use to transcribe the call audio. (Example for GPU setups: "Systran/faster-whisper-large-v3")
- Enter the spoken language used in calls if known as it will improve the performance. Leave blank to allow for automatic detection.
- Enter the sampling Temperature, the value should be between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. If set to 0, the model will use log probability to automatically increase the temperature until certain thresholds are hit.
- Check the "Enable Voice Activity Detection (VAD) filter" to enable the "Speaches" server to remove silence longer than 2 seconds (Silence length can be changed on the "Speaches" server configuration).
- Check the "Enable Phrase prompts" to send the Talkgroup and Radio labels along with the added Keyword phrases as "prompts" to help improve accuracy. Note:Sometimes the prompts can influence the model when it hallucinates and cause it to include and repeate the prompt words, this is most often seen in short calls that don't contain spoken words.
- To skip transcribing short duration calls, enter in a millisecond value. Short calls without any spoken words are more likely to get transcribed as random text.
- Click the "Call transcribe" tab.
- Select the "Talkgroups to transcribe" option and the corresponding talkgroups you want transcribed after each call is recorded.
- Click the "Keyword Phrases" tab and enter any extra keyword phrases you need to help improve accuracy of the speech recognition. After a few calls have been processed, you will start to notice if extra phrases are needed.
- Click the "Save" button
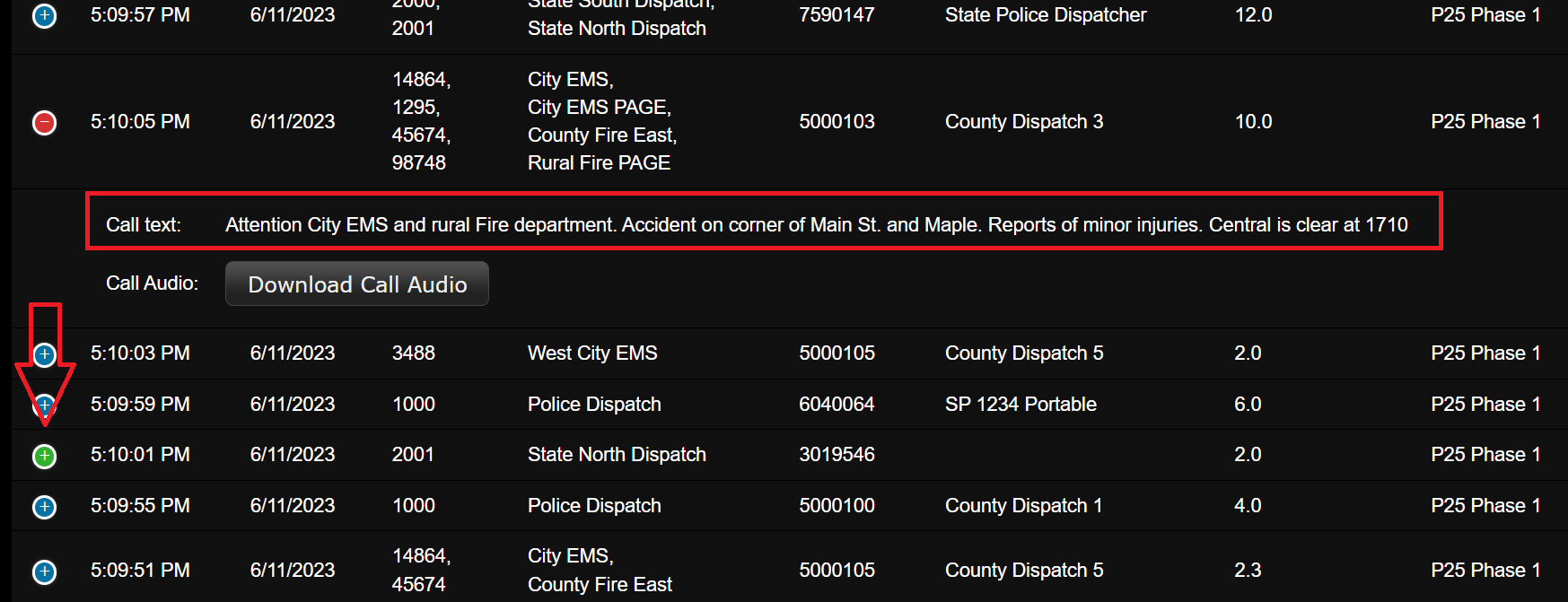
- If configured correctly all newly recorded calls for the selected Talkgroups will display the call transcription text on the Trunking Recorder Web Interface. Note: Transcribed Calls will display a green colored plus sign to the left of the time. Click the plus sign to expand the Call details.
- Also, all new Call notification emails will include the transcribed call text in the email.
- If any errors are encountered, they will be logged in the Trunking Recorder log file.
Note: For more information on the various Whisper options see the OpenAI Whisper API documentation.